Improving the Procedural
Modelling Workflow
by Dave Pagurek
What is procedural modelling?
It's because of detail
- Adding detail in 2D
- Some is hidden
- Can be abstracted
- Adding detail in 3D
- Might not be hidden from all angles
- Need a concrete shape to render

What do you do about it?
- Copy-and-paste?
- Copy-and-paste, but with random transforms?
- Copy-and-paste, but with random transforms on individual pieces?
- Copy-and-paste, but with a tree of random pieces?
Sometimes it's easier to describe how to make instances of an object rather than make them all by hand.
Generating from grammars
Breaking sentences up into trees of grammar rules
| The | handsome | author | disseminated | knowledge | from | his | expansive | brain. |
|---|---|---|---|---|---|---|---|---|
| ARTICLE | ADJ | NOUN | VERB | NOUN | PREP | ADJ | ADJ | NOUN |
| NOUN PHRASE | NOUN PHRASE | |||||||
| NOUN PHRASE | ||||||||
| VERB PHRASE | ||||||||
| CLAUSE | ||||||||
| SENTENCE | ||||||||
Breaking sentences up into trees of grammar rules
| I | say | words. |
|---|---|---|
| NOUN | VERB | NOUN |
| VERB PHRASE | ||
| CLAUSE | ||
| SENTENCE | ||
Breaking sentences up into trees of grammar rules
| I | say | words. |
|---|---|---|
| NOUN | VERB | NOUN |
| VERB PHRASE | ||
| CLAUSE | ||
| SENTENCE | ||
| SENTENCE | CLAUSE (COMPOUND | ε) |
|---|---|
| COMPOUND | and CLAUSE (COMPOUND | ε) |
| CLAUSE | NOUN VERB PHRASE |
| VERB PHRASE | VERB (NOUN | ε) |
| NOUN | abacus | babboon | cantaloupe | ... |
| VERB | arrive | bamboozle | capitulate | ... |
Going the other way, starting from the rules
Grammars for constructing shapes
Generating drawing commands instead of sentences
- Computer reads commands sequentially and executes them
- New terminals we can work with:
- lineTo(x, y): Draw a line from the current location of the "pen" to the offset x, y
- circle(radius): Draw a circle with a given radius, centered at the pen's location
- translate(x, y): Move the location of the pen by an offset
- rotate(angle): Rotate the paper being drawn on about the pen's location
- scale(factor): Make the paper being drawn on bigger or smaller
Let's draw a tree with these tools
Let's group some things into a rule called BRANCH.
Let's draw a tree with these tools
Let's group some things into a rule called BRANCH.
Copy-and-paste that a few times
Writing that as a grammar
How would we do multiple branches?
- We would need to unwind the transformations we made
- Alternatively, we can add some new tools:
- push(): Remember the position, rotation, and scale of the paper by adding it to a stack of saved orientations
- pop(): Take the last saved paper orientation from the stack and restore it
Updating the grammar to have two branches
| TREE | translate(0, 50) NODE |
|---|---|
| NODE | BRANCH (SUB BRANCH SUB BRANCHES | ε) |
| SUB BRANCH SUB BRANCHES | scale(0.5) NODE push() rotate(-30) NODE pop() push() rotate(30) NODE pop() |
| BRANCH | lineTo(0, -50) translate(0, -50) circle(30) |
Making it less regular
Add the command random(a, b), which will generate a random number between a and b inclusive, and allow more than 2 branches:
| TREE | translate(0, 50) NODE |
|---|---|
| NODE | BRANCH (SUB BRANCHES | ε) |
| SUB BRANCHES | scale(0.5) push() scale(random(0.4, 0.8)) rotate(-30) rotate(random(-40, 40)) NODE pop() push() rotate(30) NODE pop() (SUB BRANCHES | ε) |
| BRANCH | lineTo(0, -50) translate(0, -50) circle(30) |
Some examples




It would be nice to get rid of weird results like this one.
Controlling procedural modelling
at the grammar level
Trying to make foolproof instructions
How do you keep good results but prevent bad ones like this?
| The years keep coming | and | they don't stop coming | and | they don't stop coming | and | they don't stop coming | and | they don't stop coming |
|---|---|---|---|---|---|---|---|---|
| CLAUSE | CLAUSE | CLAUSE | CLAUSE | CLAUSE | ||||
| COMPOUND | ||||||||
| COMPOUND | ||||||||
| COMPOUND | ||||||||
| COMPOUND | ||||||||
| SENTENCE | ||||||||
How to stop at 4 chained clauses?
Maybe by flattening out the recursive part of the grammar:
| SENTENCE | CLAUSE (COMPOUND | ε) |
|---|---|
| COMPOUND | and CLAUSE (COMPOUND | ε) (and CLAUSE | ε) (and CLAUSE | ε) (and CLAUSE | ε) |
| CLAUSE | NOUN VERB_PHRASE |
| VERB_PHRASE | VERB (NOUN | ε) |
| NOUN | abacus | babboon | cantaloupe | ... |
| VERB | arrive | bamboozle | capitulate | ... |
Still has limitations
- If you want a bigger number, this gets annoying
- What if you want to restrict between depths a and b?
- You can do it, but you need to be clever and you end up with a lot of manual work
Controlling procedural
modelling using search
When it becomes easier to specify how good a result is than
to specify how to only make good results
Specifying what "good" means
One way is to compare a result against a target silhouette:
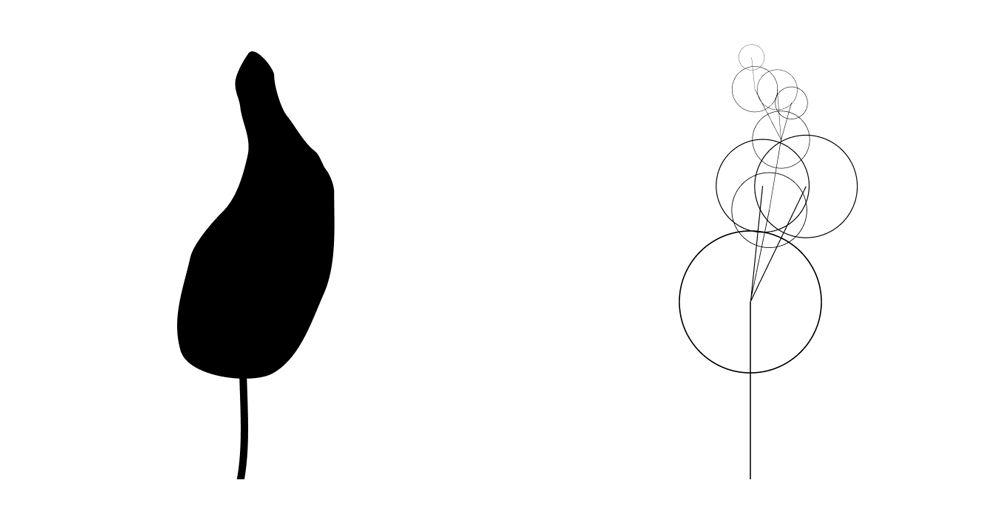
Who's that Pokémon?
Silhouette score algorithm
- Flood fill all closed areas in the image
- Set score = 0
- For each pixel x, y in the image:
- If image[x][y] == target[x][y], add 1 to the score
- Return score
Picking the best result
- Simple idea: generate a bunch of images, take the one with the highest score
- It will take a lot of image samples to find the best result
- Aside: how many would it take?
Pretend this is the Ideal Tree
Result images as probabilistic samples
The probability of a specific sample being picked depends on the choices the grammar made when generating it.
- Every time a | is used, the probability is multiplied by 0.5 because half the time it generates one option, and the other half of the time, it generates the other
- Our grammar makes one choice for every branch after the first one, and our ideal tree has eight
- The probability gets multiplied by 0.58 = 0.00390625
- As an approximation, every time random(a, b) is used, the probability is multiplied by 0.1 if we make the (generous) assumption that it picks one of 10 values between a and b and not a continuous number
- Each branch makes two of these calls, and we have eight
- The probability gets multiplied by (0.1 × 0.1)8 = 1 × 10-16
Altogether, that's around 3.9 × 10-19
Markov Chain Monte Carlo (MCMC) sampling
Instead of comparing completely random samples, branch off from a reference that you know is good.
- Pick an initial reference
- Mutate the reference to create a proposal
- If the proposal is better than the reference, make it the new reference
- If it's worse, randomly still make it the proposal, where this is less likely to happen the worse it scores
- Go back to step 2
Markov Chain Monte Carlo (MCMC) sampling
Aside: what does "mutate" mean here?
- Replace a subtree generated by the grammar with another valid one
- Mutation testing does this to check if mutants can slip past test suites
| something | = | something | + | 1 | 1 | / | 8 |
|---|---|---|---|---|---|---|---|
| VAR | VAR | OP | NUM | NUM | OP | NUM | |
| EXPR | |||||||
| EXPR | |||||||
| EXPR | |||||||
| ASSIGNMENT | |||||||
| ... | |
| ASSIGNMENT | VAR = EXPR |
|---|---|
| EXPR | (VAR | NUM) (OP EXPR | ε) |
| OP | + | - | * | / |
| ... |
In the context of images
Usually means replacing a part of the image with another
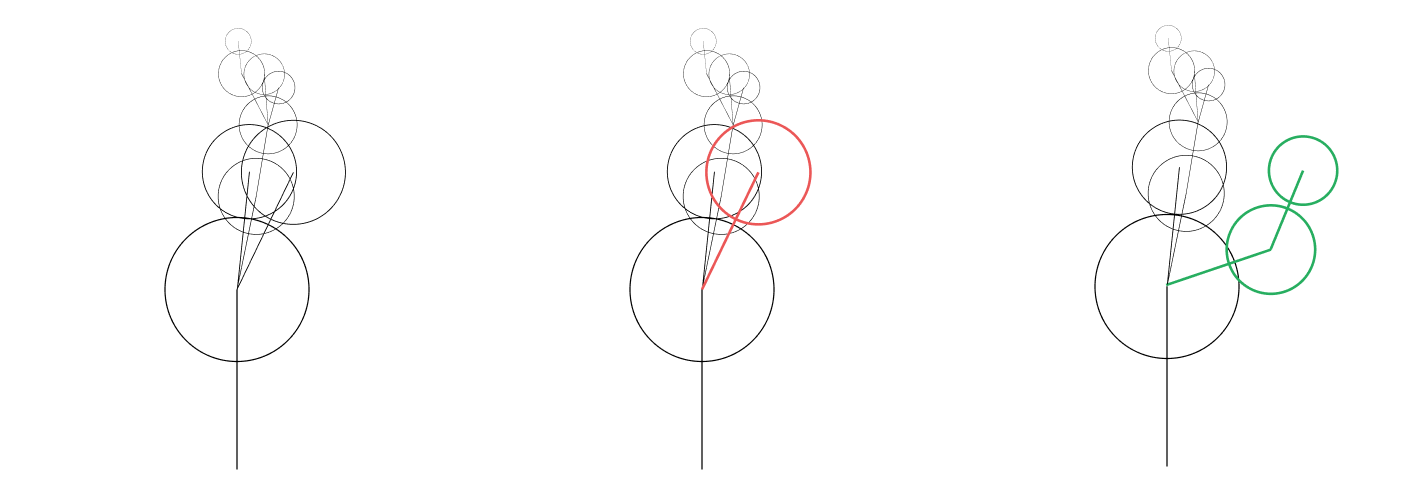
Sequential Monte Carlo (SMC) sampling
Re-rendering the whole image is slow. Instead, take samples for each piece added.
- Create n samples with the top-level grammar rule
- For each sample:
- Break down one grammar rule into some combination of terminals/other rules
- Add the score for any new shapes to the score for the sample
- Make n new samples by copying from the last set, where a higher score means it is more likely to be copied
- Go back to step 2
Sequential Monte Carlo (SMC) sampling
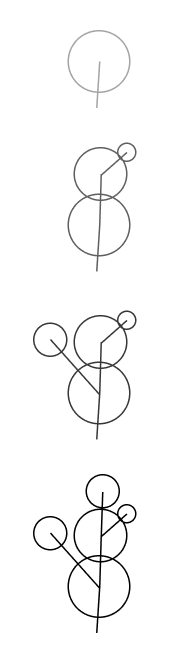
Better score functions
Scoring for 3D
- Silhouette matching is slow (~40s with a 100x100 target silhouette)
- Using a 2D silhouette target means rendering the 3D object to a silhouette, which is expensive
- A 2D silhouette would only specify the view from one angle anyway
- A 3D target volume would address this, but is also expensive
- Also it's a lot of effort to make a target volume
Properties of a good score function
- Easy for an artist to specify. They shouldn't have to create detailed 3D models to use the score function.
- A variety of models should be able to score highly. We want some amount of variation in resulting models, otherwise we wouldn't be using procedural modelling.
- Computationally inexpensive. It should be able to run at interactive rates.
- All the detail is relevant. The signal-per-effort ratio should be high, for the artist's sanity and for the algorithm to be more effective.
My solution: Model skeletons
- The thing that makes the other methods slow is the fact that they operate on geometry
- Instead, let's operate on the model's skeleton:
- Every time we encounter a push(), add a point to the skeleton
- Connect that point to the last point from the push() stack
- Each "bone" in the skeleton is just 2 points, which is cheap to operate on
Model skeleton examples




Guiding curves
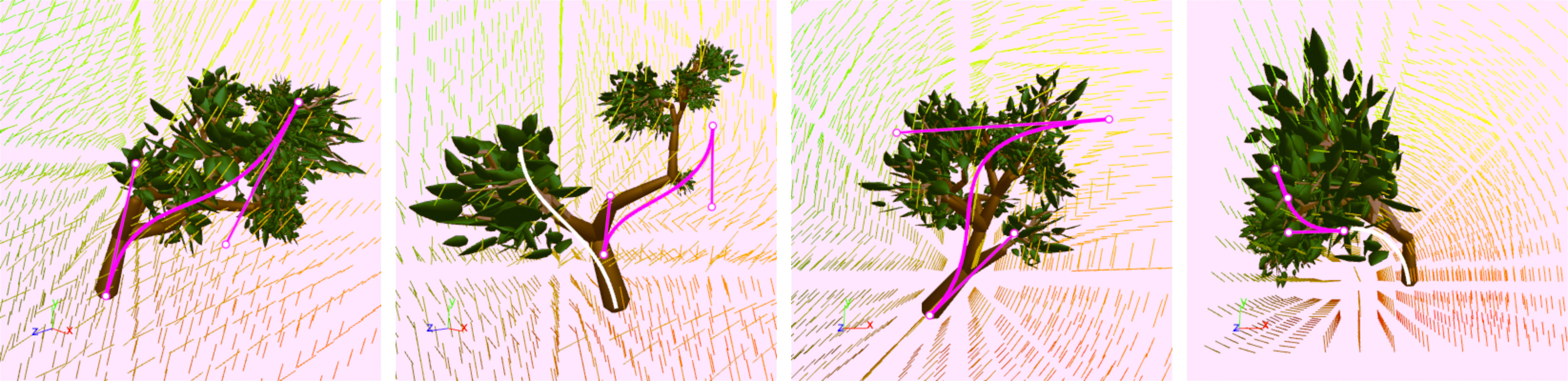
- Artists sketch curves as guides, and then the skeleton is compared to them.
- Score is based on:
- Alignment: bones score higher for being closer to the direction of the closest curve
- Distance: bones score higher for being closer to guides
- This can take under 200ms to run
Alignment

Distance
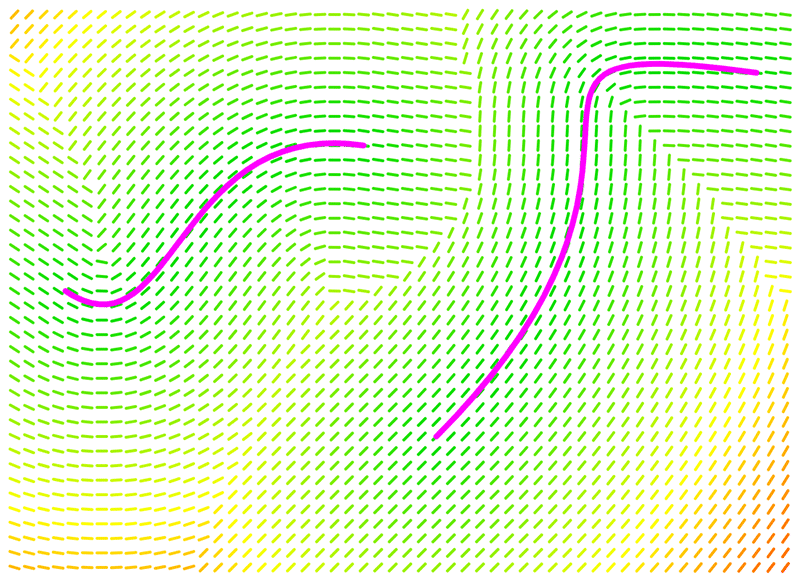
What it's like to use
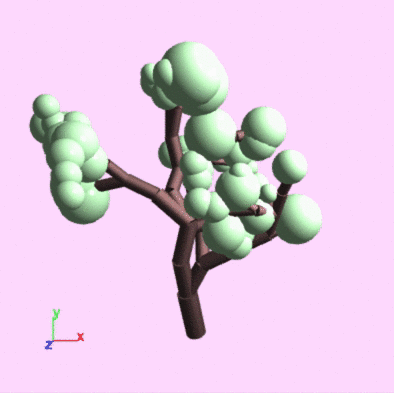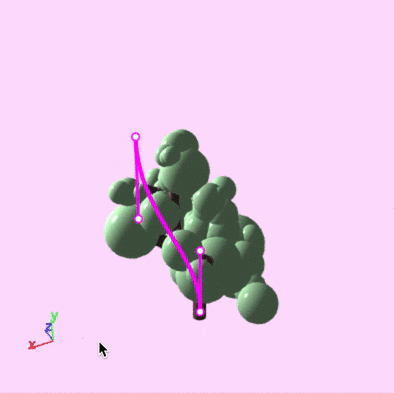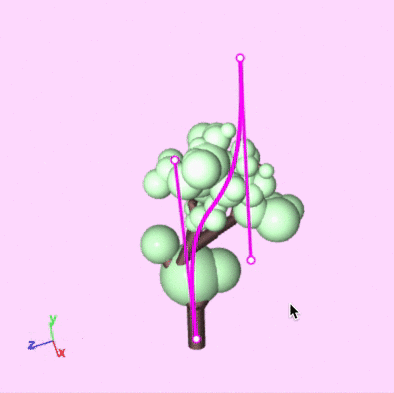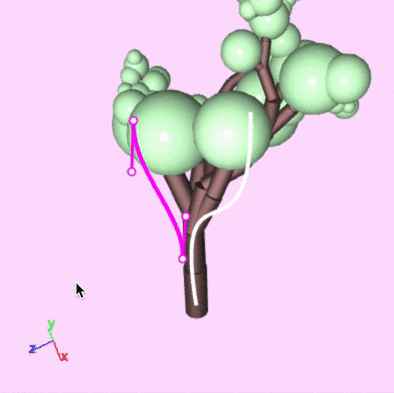
Editing environment
Split-screen with grammar and curves

What can you make with it?

What can you make with it?

What's next for this project?
- This is mostly proof-of-concept right now, could be added to a real modelling program
- Could add better support for volumes and areas
- Give guides a thickness where growth is uniformly encouraged
- Could also add target density within/around the guide
- This still requires you to write a grammar, which is not easy
- A GUI tool where grammar rules are components that can be combined would be useful
- Would also be good to visualize the distribution of results every time any randomization/choice is added to a rule
Questions?

